
如果你上网的唯一方式就是用浏览器,那么你其实错过了很多种可能。今天向大家介绍网络数据抓取(即网络爬虫),它可以让你一次查看几千甚至几百万个网页,不像狭窄的显示器窗口一次只能让你看一个网页。互联网的开放性为数据的获取带来了极大的便利,要实现网络数据抓取,可以自己动手编写程序爬取网页数据(如Python爬虫),也可以采用网络数据爬取工具,如八爪鱼等。
01网络数据爬取工具:





022自主编程开发网络爬虫:

—— 网络爬虫的原理图:——
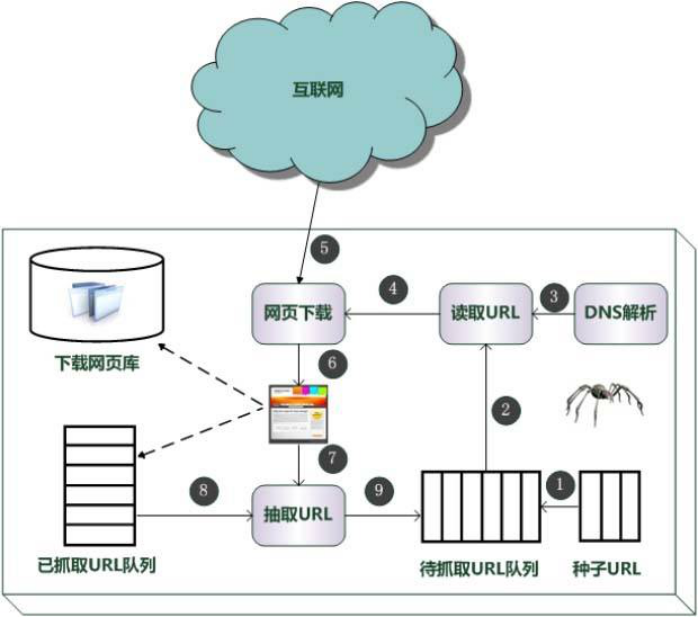
①指定一个种子URL放入到队列中。
② 从队列中获取某个URL。
③ DNS解析得到IP地址。
④ 发起网络请求。
⑤ 得到服务器的响应,此时是二进制的输入流。
⑥ 将二进制的输入流转换成HTML文档,并解析内容(我们要抓取的内容,比如标题),将解析出来的内容保存到数据库。
⑦从当前的HTML文档中,解析出页面中包含的其它URL,以供下次爬取。
⑧ 记录当前URL,并标记为已爬取,避免下次重复爬取。
⑨将还没爬取过的URL,存放到等待爬取的URL队列中。
重复以上的步骤,直到等待爬取的URL队列中没有数据。
随着数据资源的爆炸式增长,网络爬虫的应用场景和商业模式变得更加广泛和多样,较为常见的有新闻平台的内容汇聚和生成、电子商务平台的价格对比功能、基于气象数据的天气预报应用等等。一个出色的网络爬虫工具能够处理大量的数据,大大节省了人类在该类工作上所花费的时间。网络爬虫作为数据抓取的实践工具,构成了互联网开放和信息资源共享理念的基石,如同互联网世界的一群工蜂,不断地推动网络空间的建设和发展。另外,大家利用网络爬虫收集数据记住必须遵循不得妨碍他人网站正常运行这一原则。
大数据技术是当前工程和科学技术领域研究的热点。数据科学研究通常包括四个主要环节,即数据获取、数据存储、数据分析及数据可视化。前面聚焦的数据获取环节,正是其他环节的基础。及时准确地获得丰富详实的数据,可为后续工作奠定坚实的基础,并提高分析结论的可信性和可靠性。
THANKS FOR READING :)
本期图文:黄金土黄勤(师)
本期编辑:人工智能学院黄婉婷
本期责编:欧阳林艳(师)
 官方微信号:ygxg2001
官方微信号:ygxg2001
 官方微博名:阳光学院官微
官方微博名:阳光学院官微